Abstract
Stencil computations are used in a wide range of applications from physical simulations to machine-learning. Although they have been studied for several decades, optimizing and tuning them for different hardware remains challenging for most programmers.
Domain Specific Languages (DSLs) have shown that it is possible to raise the programming abstraction and offer good performance at the same time. However, these approaches require DSL writers to write an almost full-fledged compiler and optimizer. Current DSL compilers are often written from scratch with none or little reuse between different ones. The Lift project has recently emerged as a new approach to achieving performance portability. Lift is based on a small set of reusable parallel primitives targeted by DSLs or library writers. Lift's key novelty is its encoding of optimization as rewrite rules which are used to explore the optimization space. This approach is easily extensible and requires very little effort from compiler writers to support other domains. However, Lift has mostly focused on linear algebra operations and it remains to be seen whether this approach achieves performance portability across domains.
We propose to put this to the test and extend Lift with support for stencil computations. By leveraging the existing Lift primitives and optimization, we only add a small number of primitives together with a few rewrite rules. Performance results on several stencil applications show that this approach leads to high performance on different GPUs.
The Lift Project

Figure 1: Compilation Process of Lift
Lift provides high-level functional primitives, as shown on the left-hand side, which serve as the building blocks used by the programmer. Applications are expressed by composing and nesting these primitives which are well-known operations in functional programming, such as map and reduce. Using a functional approach enables expressing multidimensional stencil computations by composing and nesting intuitive primitives. Furthermore, systematically transforming programs using semantics-preserving rewrite rules allows correctness to be proved with simple equational reasoning.
Lift achieves performance portability by formalizing both algorithmic and device specific optimizations as a sequence of rewrite rules. An automatic exploration process, shown in the middle of Figure 1, applies these optimization rules to find the best performing implementation for each device [SRD16]. Crucially, Lift offers a clear separation of concerns between what should be computed and how it should be implemented. High-level expressions specifying what to compute are automatically rewritten into low-level expressions which specify how to compute it. This is the key idea for achieving performance portability in Lift. The low-level expressions are still functional in nature but encode specific aspects of the OpenCL programming model such as OpenCL's thread or memory hierarchy.
Finally, the Lift tool-chain produces high performance OpenCL code, as shown on the right-hand side. Our compiler infers types, performs memory allocation, and computes indices into arrays which are implicit in the functional notation [SRD17].
Extending Lift for Stencil Computations
Stencil computations are a class of algorithms which update elements in a multidimensional grid based on neighboring values using a fixed pattern - the stencil. They are used extensively in various domains such as medical imaging, fluid simulations, numerical methods or machine-learning. In general, stencil computations consist of three fundamental parts as shown in Figure 2: (a) for every element of the input, a neighborhood is accessed specified by the shape of the stencil; (b) boundary handling is performed which specifies how to handle neighboring values for elements at the borders of the input grid; (c) finally, for each neighborhood their elements are used to compute an output element.
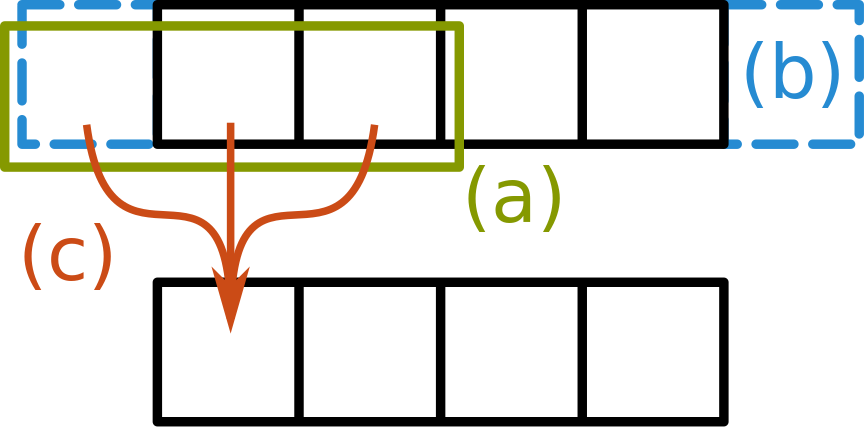
Figure 2: 3-Point Stencil |

|
The most relevant high-level primitives in Lift are map, reduce, zip, iterate, split, and join, whose types are defined in [SFLD15]. It is not possible to express stencil computations in Lift using solely the primitives. These primitives are too restrictive in terms of data accesses such that it is not possible to express accessing neighborhoods of elements which is mandatory for stencil computations. Instead of expressing stencil computations using a single high-level stencil primitive, as often seen in other high-level approaches , in Lift, we aim for composability and, therefore, express stencil computations using smaller intuitive building blocks. We add new primitives to perform the first two steps. Following the original design goal of Lift, each primitive expresses a single algorithmic concept and more complex functionality is achieved by composition.
Boundary handling with pad
The new pad primitive adds ![]() and
and ![]() elements at the beginning and end of the input array
elements at the beginning and end of the input array ![]() respectively.
There are two variations of pad which either re-indexes into the
input array, or appends a user-specified value.
respectively.
There are two variations of pad which either re-indexes into the
input array, or appends a user-specified value.
The pad primitive for reindexing has the following type:
It uses the index function ![]() to map indices from the range
to map indices from the range ![]() into the smaller range of the input array
into the smaller range of the input array
![]() .
The elements added at the boundaries are, therefore, elements of the input array and the index
function is used to determine which element this will be.
For instance, by defining the following function: clamp(i, n) = (i < 0) ? 0 : ((i
>= n) ?
n-1 : i),
it is possible to express a clamping boundary condition.
The pad primitive for appending values has a similar type and can be
used to implement constant boundary conditions.
.
The elements added at the boundaries are, therefore, elements of the input array and the index
function is used to determine which element this will be.
For instance, by defining the following function: clamp(i, n) = (i < 0) ? 0 : ((i
>= n) ?
n-1 : i),
it is possible to express a clamping boundary condition.
The pad primitive for appending values has a similar type and can be
used to implement constant boundary conditions.
Creating neighborhoods with slide
The slide primitive applies a sliding window of length ![]() which progresses
which progresses ![]() number of elements.
To create a one-dimensional three-point stencil we write:
number of elements.
To create a one-dimensional three-point stencil we write:
![]() .
This creates a nested array where each element of the outer array is itself an array of three
elements.
The type of slide is defined as follows:
.
This creates a nested array where each element of the outer array is itself an array of three
elements.
The type of slide is defined as follows:
Computing the stencil for each neighborhood with map The map primitive is the principle and only way in Lift to exploit data parallelism. As stencils are naturally data parallel we express the last step of the stencil computation using the map primitive. This step takes a neighborhood as its input and performs the stencil computation to produce a single output value for each neighborhood. Listing 1 shows a simple 3-Point Jacobi Stencil expressed in Lift. We can clearly see the decomposition in three logical steps. The stencil computation performed on each neighborhood is specified as the function sumNbh in line 1.
One of the crucial ideas of Lift is to express complex computations as compositions of simple and easy to understand one-dimensional primitives. Using nesting and function composition, we are able to express multidimensional stencil computations without introducing specialized primitives for higher dimensions. This keeps the compiler simple as it only generates code for intuitive one dimensional primitives. Furthermore, we are able to hide the complexity of composition and nesting behind high-level, domain-specific functions.
Expressing Stencil Optimizations as Rewrite Rules
On GPUs the fast, but small local memory can be used as a cache to store a set of neighborhoods where their elements are loaded only once from the slow global memory and successive accesses are made from the local memory. Traditionally, locality is exploited using overlapped tiling [GBFP09]. The input grid is divided into tiles, which overlap at the edges to allow every grid element to access its neighboring elements. The size of the overlap is determined by the size of the neighborhood.
We reuse the slide primitive to represent overlapping tiles. By phrasing tiling as a rewrite rule this optimization is made accessible to Lift's automatic exploration process. Tiling in one dimension is expressible using the following rewrite rule:

As with the primitives, the optimization rules for tiling higher dimensional stencil are expressed reusing the one-dimensional primitives.
Evaluation

Figure 3: Performance of the Lift generated code and hand-optimized kernels expressed as Giga-elements updated per second.

Figure 4: Performance of Lift-generated kernels compared to PPCG-generated kernels. Both approaches auto-tune the kernels for up to three hours per benchmark/input/device. Large input sizes did not fit onto the ARM GPU.
The transformation from high-level programs to OpenCL code is performed automatically by applying rewrite rules to explore optimizations such as the overlapped tiling, usage of local memory, or loop-unrolling. By exploring different optimization choices on different devices, Lift achieves performance portability. We tune numerical parameters such as tile sizes and explore this search space to find the best performing kernel for each stencil applications. The results presented in Figure 3 show the performance of Lift generated code with hand-optimized reference implementations. Figure 4 shows the performance of Lift generated kernels compared to state-of-the-art polyhedral compilation.
References
[SFLD15] Michel Steuwer, Christian Fensch, Sam Lindley, and Christophe Dubach. Generating performance portable code using rewrite rules. In ICFP, pages 205-217. ACM, 2015.
[SRD16] Michel Steuwer, Toomas Remmelg, and Christophe Dubach. Matrix multiplication beyond auto-tuning: rewrite-based GPU code generation. In CASES, pages 15:1-15:10. ACM, 2016.
[SRD17] Michel Steuwer, Toomas Remmelg, and Christophe Dubach. Lift: a functional data-parallel IR for high-performance GPU code generation. In CGO, pages 74-85. ACM, 2017.
Publications
- Bastian Hagedorn: An Extension of a Functional Intermediate Language for Parallelizing Stencil Computations and its Optimizing GPU Implementation using OpenCL; Master Thesis; University of Münster, Germany; Supervised by Sergei Gorlatch and Michel Steuwer.